


Abstract
Background: Military service exposes personnel to unusual situations with unclear health-related implications, and to identify both immediate and delayed risks, part of health surveillance includes examination of mortality and cancer rates that extends beyond periods of military service. The main aim of the Canadian Forces Cancer and Mortality Study II (CFCAMS II) is to describe the mortality and cancer experience of Canadian Armed Forces personnel (serving and released; about 230 000 people), with the further aim of informing health promotion and prevention programs for serving personnel and services for veterans after they leave the military.
Methods: This protocol is for a retrospective cohort study of serving and released Canadian Armed Forces personnel who enrolled on or after Jan. 1, 1976 in the Regular Force or Class C of the Reserve Force. To create our cohort, we identified record-linkage methods as the most appropriate mechanism to study mortality and cancer in those with a history of Canadian military service. Statistics Canada will link the CFCAMS II cohort file to the Canadian Vital Statistics (Mortality) and Canadian Cancer Registry databases for outcomes up to Dec. 31, 2014. The linkage will be stored in their highly secure linkage environment. Statistical analyses will be broadly divided into mortality and cancer incidence.
Results: We will quantify mortality and cancer morbidity incidence and survival using multiple established methods, as well as age–period–cohort regression models to describe the relation between military service and mortality and cancer outcomes.
Interpretation: The findings will represent novel and sound evidence on the risks and protective factors of military life.
As a military organization, the Canadian Armed Forces has the challenge of balancing its defence mandate responsibilities with its duty to protect its personnel. The nature of its operations can be accompanied by unusual exposures, with both expected and unknown risks to personnel. Adverse outcomes, including death, may occur. To identify immediate and delayed risks, the Canadian Armed Forces has included cancer and mortality surveillance as part of its health surveillance strategy for over 15 years. This strategy includes a broad cross-section of methodological approaches and data sources, documenting the various stages of the military life course, as they pertain to long-term health outcomes.1 This has included cluster investigations, record linkage studies2,3 and surveillance systems.4,5
The Canadian Armed Forces’s latest record-linkage study, the Canadian Forces Cancer and Mortality Study II (CFCAMS II), has been developed to address remaining evidence gaps. As such, the underlying hypothesis of the CFCAMS II is that military service has a differential effect on mortality and cancer incidence. Specifically, the study’s main aim is to describe the mortality and cancer experience of Canadian Armed Forces personnel (serving and released). The evidence from this study will be used by the Canadian Armed Forces to inform health promotion and policies for serving personnel, as well as by Veterans Affairs Canada in their provision of care and services for veterans and their families after they leave military service. Specific research questions include: What is the burden of mortality among those with a history of military service? and Are any occupational factors strong predictors of excess mortality or cancer incidence among those with a history of military service?
Methods
This protocol is for a retrospective cohort study of serving and released Canadian Armed Forces personnel.
Participants
The CFCAMS II is a longitudinal record-linkage study that will describe the mortality and cancer incidence burden among all Regular Force and Class C Reservist personnel enrolled by the Canadian Armed Forces for the first time between 1976 and 2015 inclusive. In other words, the study population is the full population (i.e., this study is a census), and, consequently, no exclusion criteria exist beyond initial enrolment outside this time frame.
Defining and building the cohort
The 1976 starting point was chosen because of the availability of administrative information in the Central Computerized Pay System (CCPS), an electronic Department of National Defence data set with information available beginning in 1976. Pre-1976 data exist within the CCPS, but their completeness is questionable. By using 1976 as the cohort start year, cohort completeness (and the resultant census-like nature of the cohort) will be ensured.
The CCPS includes Regular Force and Class C Reserve Force (reservists on international operations and/or tours of duty) members. Data in the CCPS have an advantage in terms of accuracy and precision over human resources data when used to identify membership in the CFCAMS II cohort and other information associated with remuneration. They also have a built-in feedback mechanism whereby both service members and the employer are motivated to rectify remuneration errors as soon as possible. This creates an informal data validation process that did not exist for the CFCAMS I.6
Class A and B Reserve Force personnel are excluded from this cohort. The rationale is described in more detail in section I of Appendix 1 (available at www.cmajopen.ca/content/6/4/E619/suppl/DC1).
Using data extracted from the CCPS, epidemiologists from the Directorate of Force Health Protection created a cohort file (Figure 1). This cohort file was supplemented and validated with the use of human resources data, thereby minimizing missing information and resolving imprecise or apparently anomalous information (e.g., unrealistic birth date). Access to and use of these data files were considered to be consistent with the purpose for which these data were collected and maintained (i.e., “consistent use”) under the Canadian Government Info Source program.

Flow chart showing the Canadian Forces Cancer and Mortality Study II (CFCAMS II) cohort-building process. Note: CCPS = Central Computerized Pay System, HRMS = Human Resources Management System, MOSID = Military Occupation Structure Identification code.
Data elements included in the cohort file submitted to Statistics Canada are catalogued in Table 1. Multiple enrolments and releases (if relevant) are also captured. Data quality considerations with the use of CCPS data to create the cohort file are described in section II of Appendix 1.
Data elements in the Canadian Forces Cancer and Mortality Study II cohort file
Data linkage
Statistics Canada’s Social Data Linkage Environment is a highly secure linkage environment that facilitates the creation of linked population data files for social analysis. At the core of the Social Data Linkage Environment is a Derived Record Depository, a national dynamic relational database containing limited personal identifiers. The depository is created by linking selected Statistics Canada source index files to produce a list of unique individuals. These files, which contain personal identifiers without analysis variables, are brought into the Social Data Linkage Environment, processed and linked to the Derived Record Depository. Updates to these data files are linked to the depository on an ongoing basis. A more detailed explanation of the data linkage process is provided in section III of Appendix 1.
For the CFCAMS II, the cohort file provided by Statistics Canada will be linked to 2 discrete data holdings within the Social Data Linkage Environment: the Vital Statistics – Death Database and the Canadian Cancer Registry. No civilian data from other sources will be used.
The Vital Statistics – Death Database provides mortality information from 1950 onward to the latest available year of data. Information from the database is provided by the International Classification of Diseases (ICD) code version in effect at the time of death. Cause of death information is recorded by vital statistics registries in the provinces and territories, with follow-up for these records taking years to complete. The provinces and territories share their information (under the Statistics Act) with Statistics Canada for national reporting and to allow linkage for approved projects.
The Canadian Cancer Registry contains cancer incident events from 1969 onward to the latest available year of data. All new incident cases of cancer are recorded by cancer registries in the provinces and territories. People can have more than 1 record in the registry depending on how many cancers have been reported or how many registrations have been submitted for a given person. Cancer incidence information in the Canadian Cancer Registry is coded to the ICD code version in effect at the time of registration. This can be years after the date of diagnosis, allowing for the follow-up required to confirm the diagnosis and complete the registration. The registries then share their information (under the Statistics Act) with Statistics Canada for national reporting and to allow linkage for approved projects.
Specific mortality (outcome) variables to be requested are date of birth, sex, province or country of birth, province of residence at time of death, province/country of death, full date of death, underlying cause of death (ICD code), all causes of death (for deaths in 2000 onward owing to Vital Statistics – Death Database holdings) and autopsy code. Malignant tumour variables to be requested are listed in Table 2. Their quality is discussed in section II of Appendix 1, and expected timelines are given in Figure 2.
Requested Canadian Cancer Registry data elements
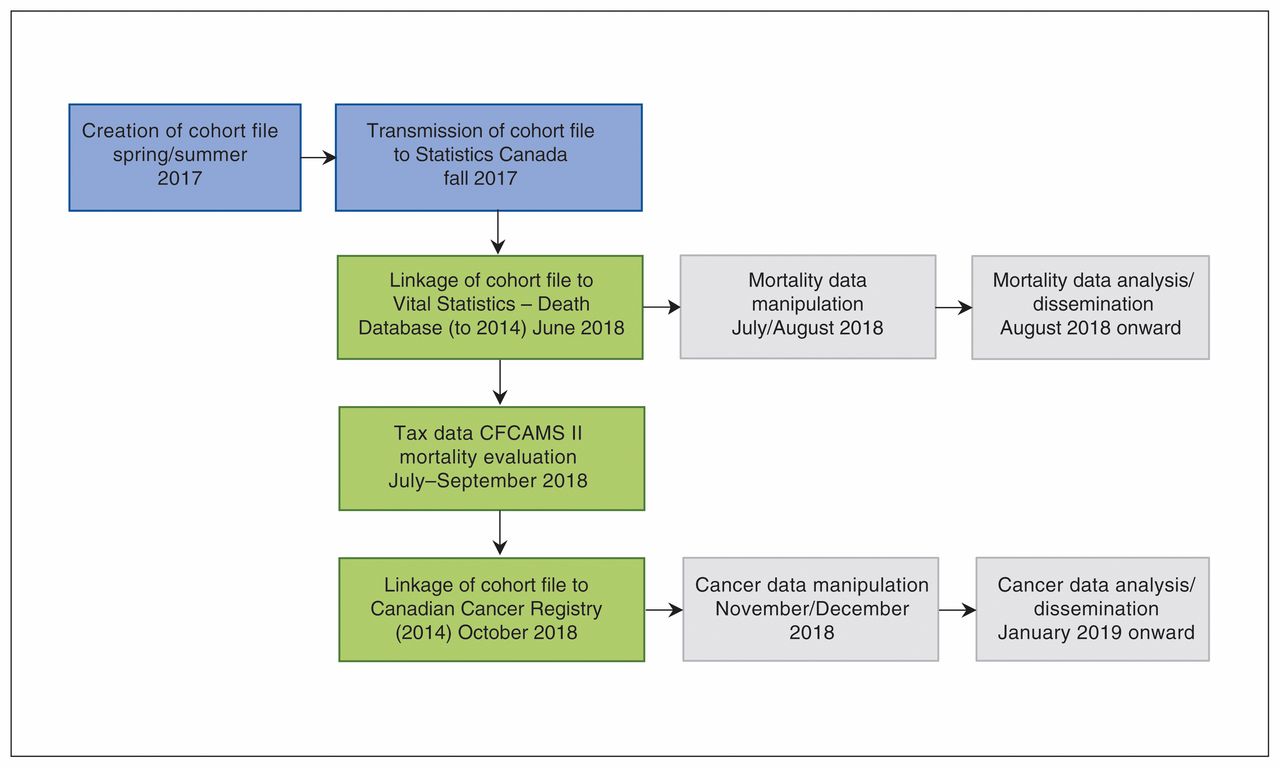
Expected timelines for the Canadian Forces Cancer and Mortality Study II (CFCAMS II).
Living cohort
As the Canadian Armed Forces military cohort continues to grow over time, the addition of new records for new enrollees, as well as updates to existing cohort records held in the Social Data Linkage Environment are planned. In turn, these will periodically be relinked to the Vital Statistics – Death Database and Canadian Cancer Registry, providing more person-years of observations, more outcome data and the ability to study the possible impact of new military actions on health outcomes.
Sample size and power calculations
One of the main strengths of the CFCAMS II is that the study population is a census. This eliminates sampling error and the corresponding need for sample size calculations.7,8 Given that a priori power calculations imply that sample size can be modified in response to poor power, it is of poor limited usefulness in this census-like context. However, outcome projection models were built and are presented in section IV of Appendix 1, and post hoc power calculations will be derived when answering any of the study questions.
Preanalysis data manipulation
Before data analysis can begin, some study data editing/manipulation will be required. These considerations are described in more detail in section V of Appendix 1, and the proposed derived military service variables are presented in the latter half of Table 1.
Statistical analyses
Statistical analyses will be broadly divided into mortality and cancer incidence. An overview of the proposed incidence and/or prevalence, survival and regression methods within these 2 subsets is presented in Table 3. Analyses will be conducted with Stata 14 (StataCorp).
Overview of proposed analyses, by data type
Considerations
All analyses assume sufficient power to respond to the research question(s).
Whenever possible, analyses will be:
○ Stratified by sex or by serving status. If a research question justifies it, analyses may also be stratified by component (Regular Force only, Class C Reserve Force only, combination of Regular Force and Class C Reserve Force service).
○ Age- and sex-adjusted.
Cancer analyses will include only invasive malignant neoplasms.
For cancer incidence data, multiple primary cancers will be identified with the use of the International Agency for Research on Cancer rules,9 per Statistics Canada practice.10
Mortality
For the purpose of our analyses, mortality will be classified in 3 ways: 1) all-cause mortality, 2) cause-specific mortality and 3) population- or deployment-specific mortality.
Incidence
Incidence will be presented as follows:
Incidence rates per 100 000 observed person-years.
○ The use of observed person-years as a denominator is a more exact measure of population time at risk,11 particularly in a dynamic cohort.
Standardized mortality ratios12 (see section V of Appendix 1 for more details).
Lexis diagrams:13
○ Present incidence data where age–period–cohort effects are likely to influence mortality rates over a long follow-up period.
○ Particularly useful in visually communicating temporal and population subset differences in incidence.
Survival
Bakker and colleagues14 stated that “the purpose of survival analysis … is to estimate a patient’s chances of survival as a function of time,” and it does so using both censored and uncensored observations15 (which traditional regression models cannot do). Survival methods will include:
Kaplan–Meier survival analysis:
○ Primarily to study survival trends of more frequent causes of death.
○ We will estimate multiple survival curve differences using log-rank tests, except where earlier and later separations between survival curves might be differentially weighted, in which case alternative tests (e.g., Wilcoxon) will be considered.
Cox proportional hazards regression:
Competing hazards models will not be included, given limited historical data on underlying causes of death.18
Regression models
Age–period–cohort modelling will also be used, as it also controls for secular (“period”) influences, as well as era (“cohort”) influences on rates over time.19 With the use of the Stata “apcfit” command,20 this approach can also be used with Lexis diagrams.21
Other regression approaches (Poisson, logistic) have been considered, but published evidence suggests that adjusted parameters result in very similar results across methods22,23 or less precise estimates.23
Cancer incidence data
Cancer incidence analyses share many methodological approaches with mortality incidence analyses. Only methods specific to cancer incidence are described below.
Incidence
Incidence is one of the most common descriptive measures of cancer burden. Das24 described cancer incidence as “the number of newly diagnosed cancers of a specific site/type occurring in a specified population during a defined period.” We will quantify incidence using 1) cancer incidence rates per 100 000 observed person-years, for primary tumours only and/or all instances of multiple primary tumours, depending on the research question, sample size considerations and clinical suitability, and 2) standardized incidence ratios, which are analogous to standardized mortality ratios for first primary tumours but are focused on incident cancer cases.25 Standardized incidence ratios can also be used to quantify subsequent primary tumours, which can be particularly useful in describing the risk within a cohort of the development of secondary primary cancers.26
Prevalence
Both person-based and tumour-based prevalence will be generated, for all cancers and for leading cancers separately.10,27 The time frame(s) of the prevalence estimates will be driven by the data themselves and have therefore not yet been finalized.
Survival
The survival methods described for mortality analyses will also be used to measure cancer survival, despite debate as to the superiority of nonparametric versus parametric methods28 in generating efficient,29 unbiased survival estimates.17
Net survival is sometimes also used as a secondary measure of survival. Broadly, this approach produces a survival estimate that “might occur if cancer was the only cause of death.”30 Cause-specific net survival is strongly dependent on the completeness and consistency of registry records. In the case of the Canadian Cancer Registry, completeness is not a concern, but consistency may be, as records are collated from different provincial and territorial registries, where different cause of death selection and coding rules may prevail. Consequently, we will also calculate relative net survival, when relevant, using the Stata “stns” command,31 which employs the Pohar-Perme estimator approach to calculating net survival.32 There is substantial evidence that this approach provides a less biased estimation of survival than other established approaches,30 although this varies with the length of follow-up.
Published evidence suggests that the inclusion of subsequent primary tumours in survival analyses differentially reduces survival estimates; the magnitude of this reduction depends on both the type of cancer in question and the proportion of multiple primary tumours.33 As with any decisions requiring clinical and epidemiological considerations, we will seek external expertise before analysis.
Regression models
In addition to the age–period–cohort regression models described in the mortality analysis section, we will consider Joinpoint models34 when building predictive cancer incidence models, given that they are commonly used35 by the National Cancer Institute Surveillance, Epidemiology, and End Results (SEER) Program36 and the International Agency for Research on Cancer.
Missing values and sensitivity analyses
Although missing data can be challenging, the CFCAMS II will rely on administrative data that are collected with the use of stringent data-completeness standards. This, combined with the high quality of the pay data (used to create the study cohort), means that broad, systematic missing data requiring a management protocol are not likely to be an issue.
A more likely source of missing data will be deaths and cancer diagnoses that took place outside of Canada. To address the mortality gap, we have contracted Statistics Canada to use tax records to identify people who died outside of Canada. Although no cause of death will be available, this will allow us to determine the magnitude of the issue and to use this information to conduct sensitivity analyses on reported mortality. We will also conduct cancer incidence sensitivity analyses, using the proportion of cancer incidence to deaths and the proportion of reported to nonreported deaths. In both cases, different scenarios will be evaluated to provide a range of levels of sensitivity.
Dissemination
The results from the study will be disseminated within the involved organizations as well as to the general public, through publication and dissemination in peer-reviewed journals.
Ethics and privacy
The CFCAMS II protocol was reviewed and approved by an external institutional review board (Quorum Review, reference no. QR#31460CDN/1). A consent waiver was requested and was approved by the review board, which allows the study to be conducted without the individual consent of all participants (per Article 3.7 of the Canadian Tri-Council Policy Statement: Ethical Conduct for Research Involving Humans37). Additional redundant mechanisms will be implemented to ensure that study population privacy and data are rigorously protected (see section VI of Appendix 1).
Interpretation
The CFCAMS II aims to describe the mortality and cancer experience of Canadian Armed Forces personnel using a longitudinal record-linkage design. The study will supplement existing Canadian Armed Forces and Veterans Affairs Canada health surveillance capacity to describe the burden of mortality and cancer incidence in all Regular Force and Class C Reserve Force personnel who began serving in the forces between 1976 and 2015, regardless of their current military status, and begin to investigate potential links between excess burden and military service.
The nearly 40 years of follow-up time may provide sufficient lead-up time for conditions with delayed expression following exposure (e.g., certain cancers). In addition, the large sample (about 230 000 people contributing more than 5 million person-years) may provide sufficient statistical power to investigate less common outcomes. The living nature of this study is also an important strength, as new Canadian Armed Forces members, new occupational data on existing cohort members and new outcome data for all will be periodically appended to the current cohort.
Conclusion
This study has the potential to provide novel and sound evidence on the risks and protective factors of military life. The strengths of this study make it potentially groundbreaking, particularly as it relates to evaluating the relation between military service and adverse health outcomes. The body of evidence emanating from this study will allow for the development of effective policies and programs for promoting, protecting and caring for the health of Canada’s airmen, airwomen, soldiers and sailors throughout their life courses and will provide evidence that may also benefit our allied military forces.
Footnotes
Competing interests: None declared.
This article has been peer reviewed.
Contributors: Elizabeth Rolland-Harris participated in the design of the study and drafted the manuscript. Linda VanTil, David Boulos, Mark Zamorski, Alexander Reicker, Huda Masoud, Richard Trudeau, Murray Weeks, and Kristen Simkus participated in the design of the study and helped to draft the manuscript. All of the authors gave final approval of the version to be published and agreed to be accountable for all aspects of the work.
Supplemental information: For reviewer comments and the original submission of this manuscript, please see www.cmajopen.ca/content/6/4/E619/suppl/DC1.
References
- Copyright 2018, Joule Inc. or its licensors
In this issue

{kind=link}
{kind=link}
Article tools


Related Articles
Cited By...
- No citing articles found.